NVIDIA很快在合作中启动
日期:2025-06-06 10:35 浏览:
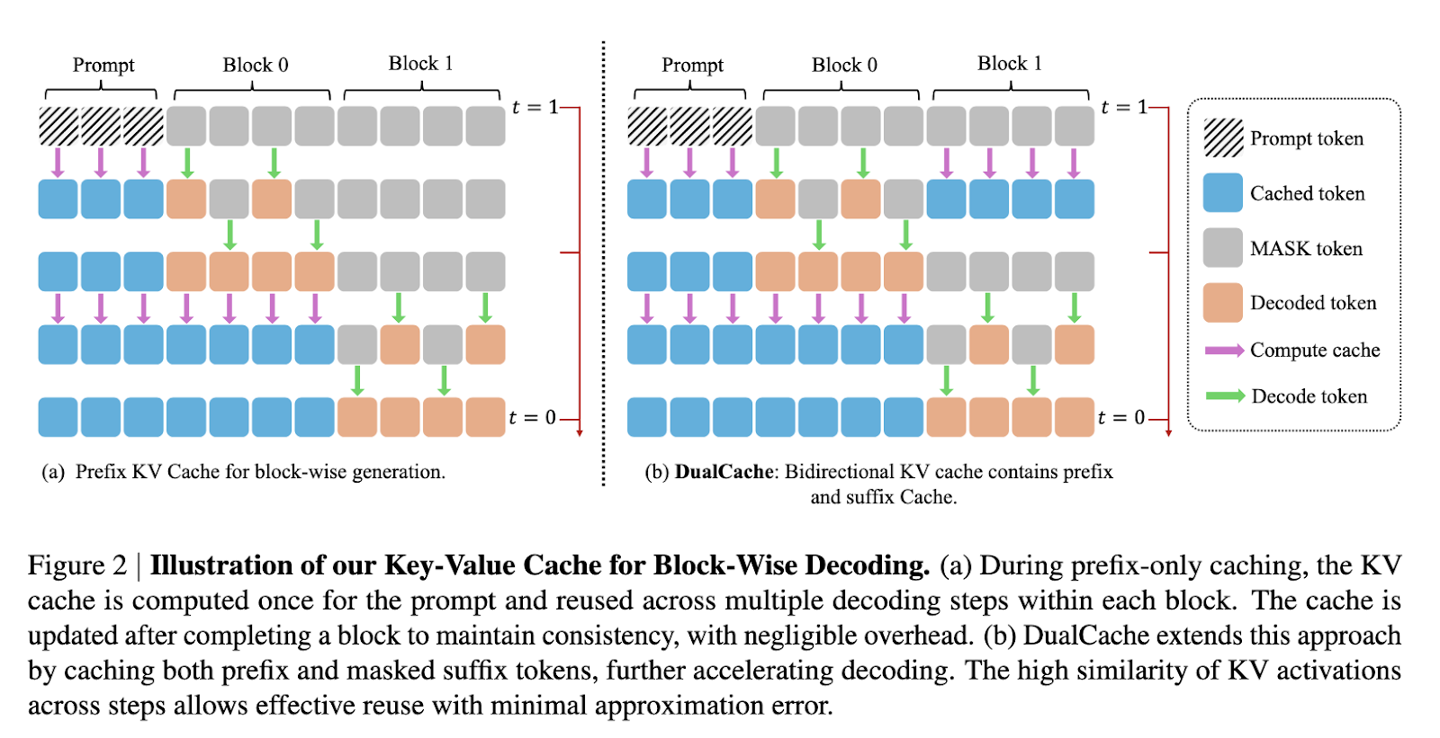
Home 6月3日报告说,技术媒体Marktechpost昨天(6月2日)发表了一篇博客文章,报道Nvidia与MIT和香港大学共同推出了Fast-DLLM框架,这大大提高了LLMS的排斥速度。扩散模型被认为是传统自回旋模型的强大竞争者。它采用了双向注意机制,理论上可以通过构建许多词汇元素来加速解码过程。但是,在实际应用中,扩散模型的识别速度通常与自回归模型相媲美。一代的每个步骤都需要重复计算所有关注状态,从而导致高计算成本。此外,当模仿同步解码时,单词元素之间的依赖性很容易破裂,并且一代人的质量被削弱,这使得他们很难满足Actual需要。它引用了一篇博客文章,并介绍了NVIDIA生成的联合团队开发了快速dllm图来解决上述瓶颈。该框架确定了两个主要变化:块状近似KV缓存机制以及对解码方法的意识的信心。 KV缓存可通过将订单分为块,预先计算和存储其他块的激活值,从而显着降低计算计算,并在随后的解码中重复使用它们。它的DualCache版本是使用相邻评估步骤的高相似性来提高效率的高速缓存前填充元素(前缀和后缀令牌)。置信度解码选择基于计划的阈值(置信阈值)的词汇元素的高度自信,从而避免了通过重合抽样和确保发电质量引起的依赖性冲突。 Fast-Dllm在许多基准测试中表现出惊人的性能。在GSM8K数据集中,当生成是1024个单词,达到了27.6倍的加速度,其8次调整的精度为76.0%;在数学基准上,多个加速度为6.5倍,精度约为39.3%;在人类和MBPP测试中,分别达到了3.2倍和7.8倍的加速度,准确性持续到54.3%和基线水平。通常,虽然Maspeed DLLM加速了,但其准确率仅下降1-2%,证明它有效地平衡了速度和质量。这项研究解决了解码的理解和质量的问题,因此扩散模型具有与实际语言生成活动中自回归模型竞争的力量,这为将来的广泛应用奠定了基础。 Home-dllm参考附在房屋上:通过启用KV缓存和平行论文解码快速dllm的无培训宣言出发LLM:无扩散llm培训的培训。KV缓存和项目接口的并行解码